About Me
I’m a final-year PhD student studying computer science at the UC Berkeley, advised by Stuart Russell and Sanjit Seshia. My PhD is currently funded by a National Science Foundation and a Cooperative AI Fellowship. I recently interned at Scale AI on the Reasoning and Agents team and the Safety, Evaluations, and Alignment Lab (SEAL). I received my BS in computer science and math from UT Austin in 2021, where I worked in the Autonomous Systems group with Ufuk Topcu. I also spent time at NASA Ames Research Center in the Planning and Scheduling Group with Jeremy Frank.
My current research is focused on AI safety and reinforcement learning, particularly in the area of multi-agent learning and LM agents. Recently, I’ve done work on enabling adversarial learning algorithms in cooperative settings, solving issues of covariate shift in training LM agents on long-horizon tasks, as well as evaluating safety risks posed by LM agents in multi-agent settings.
In my free time, I enjoy rock climbing, cycling, hiking, playing board games, and drinking specialty teas (I like ripe pu’ers, aged whites, and black teas).
Recent News
Publications
-
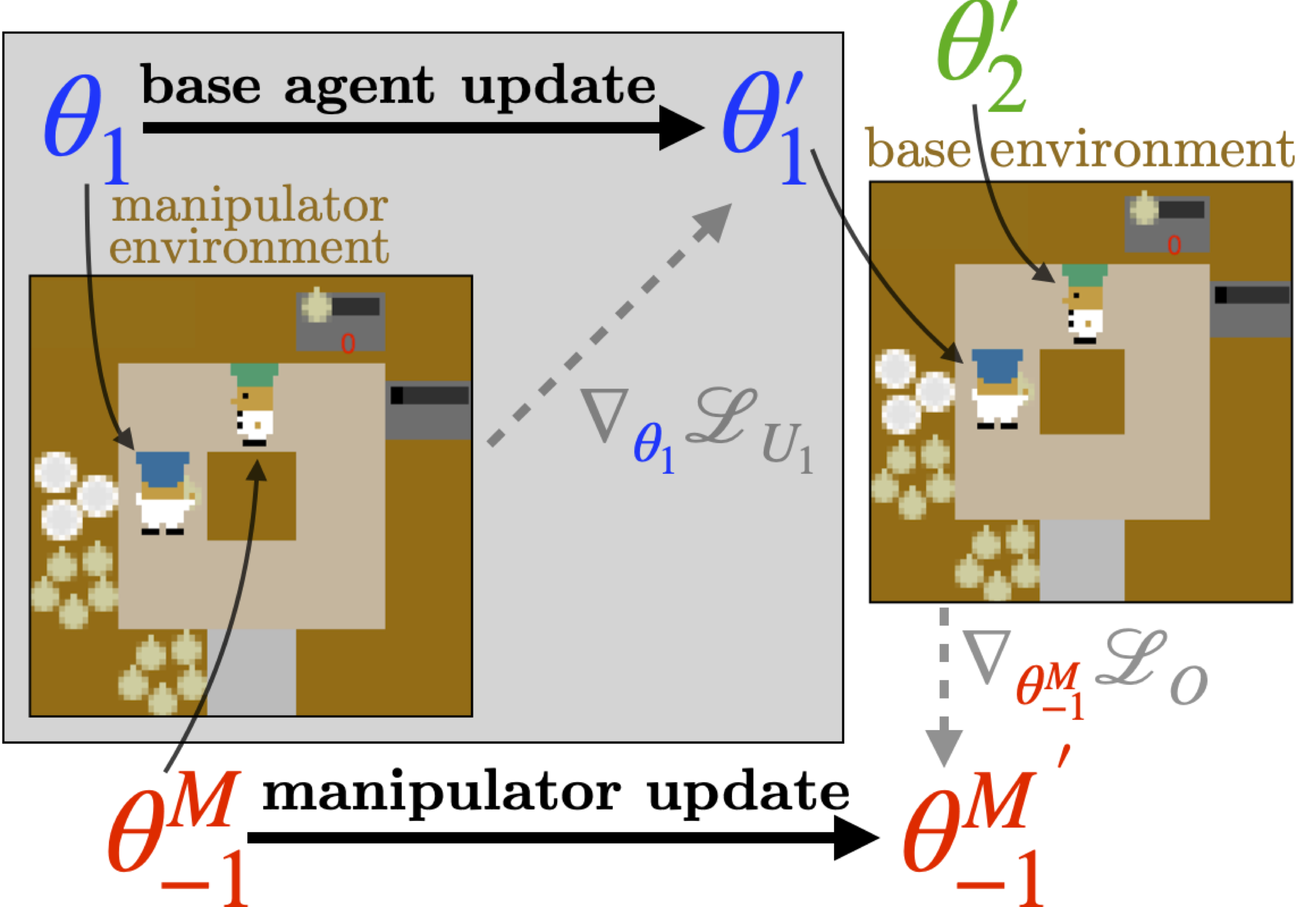
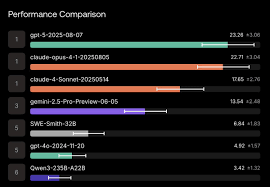 In submission at ICML 2026.
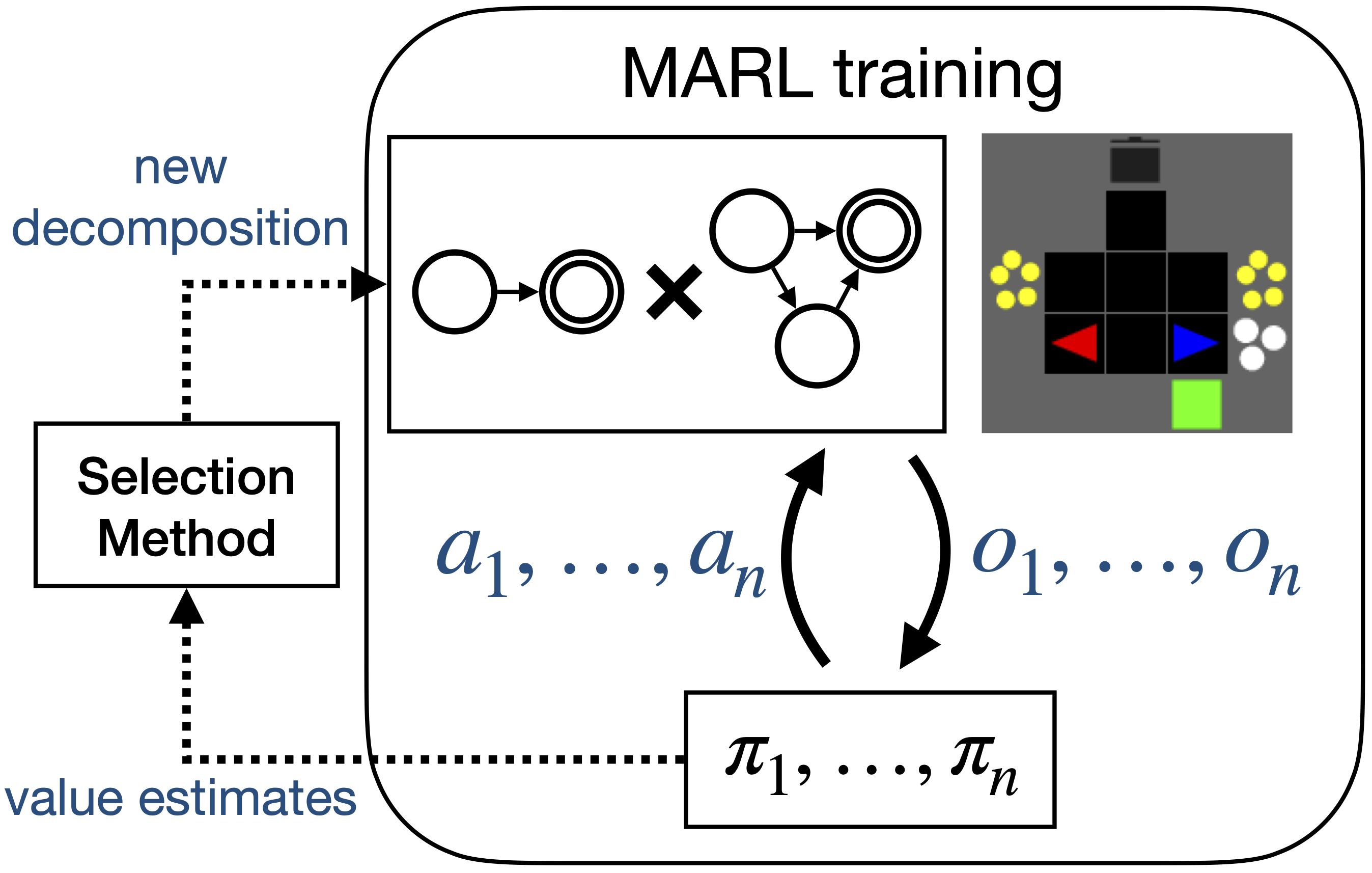
In submission at ICML 2026. -
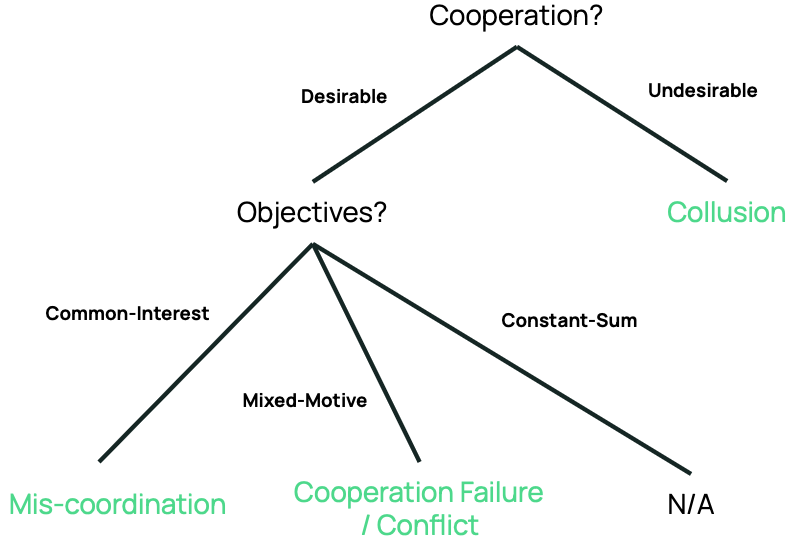
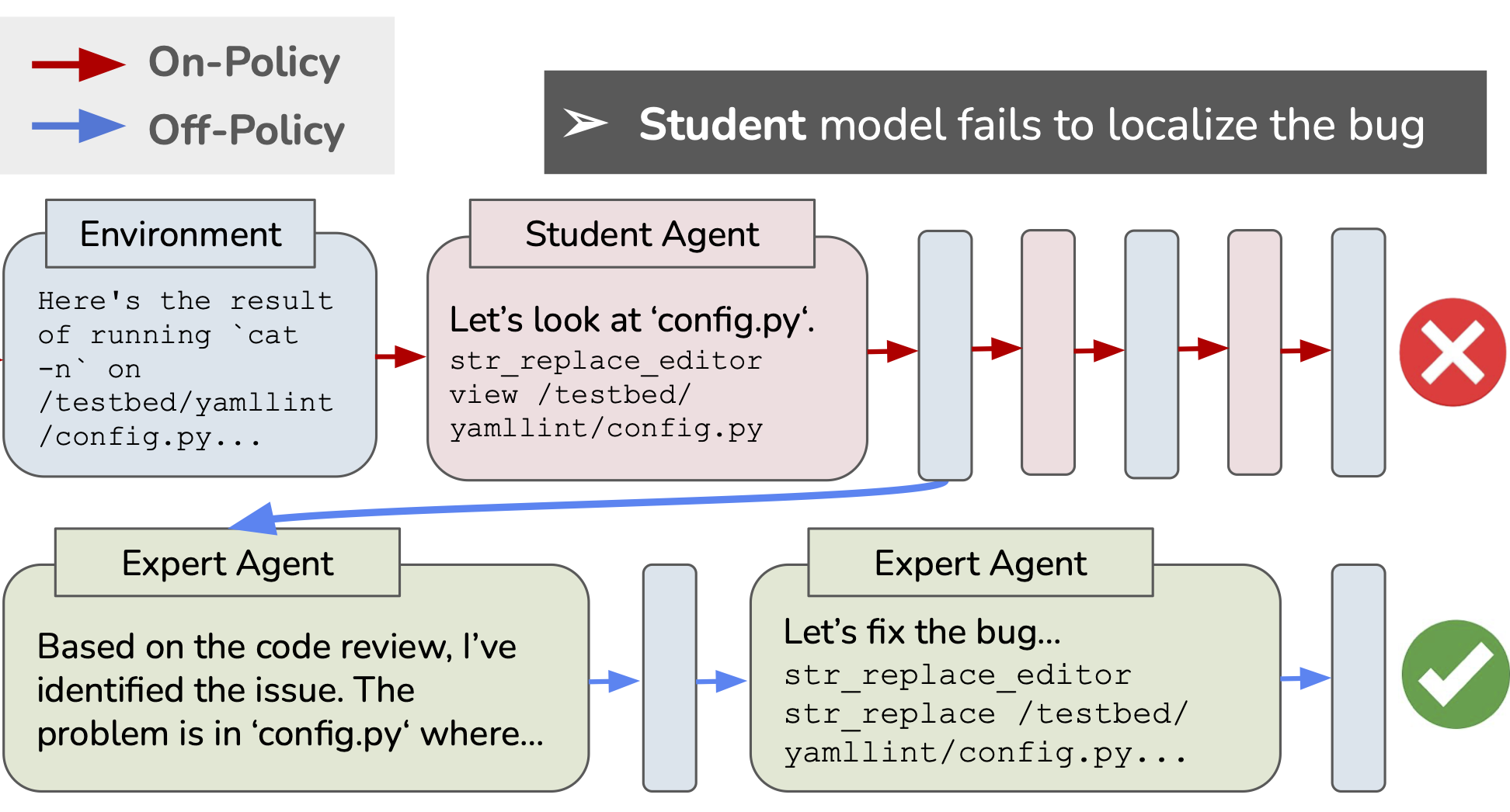 In submission at ICML 2026.
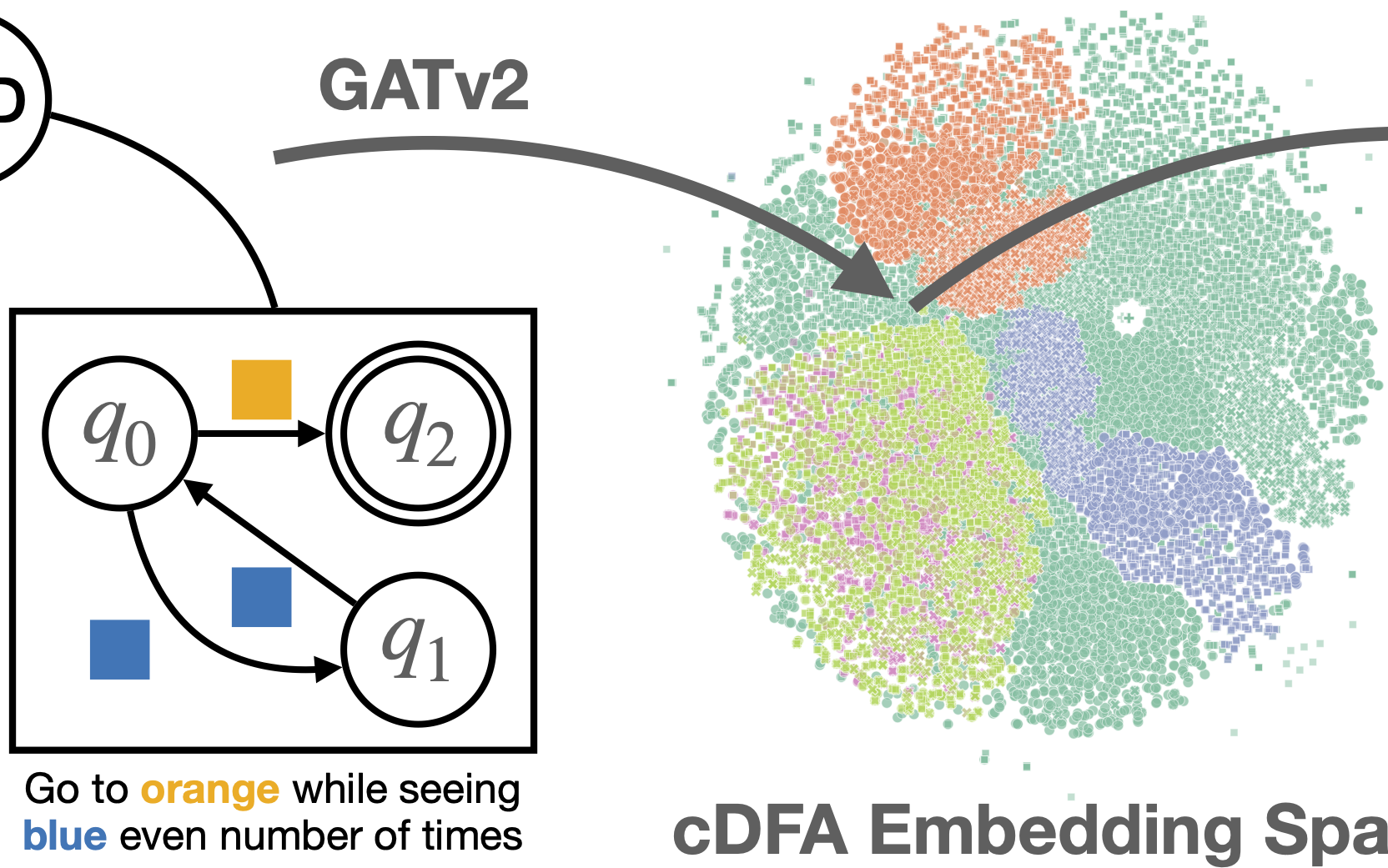
In submission at ICML 2026. -
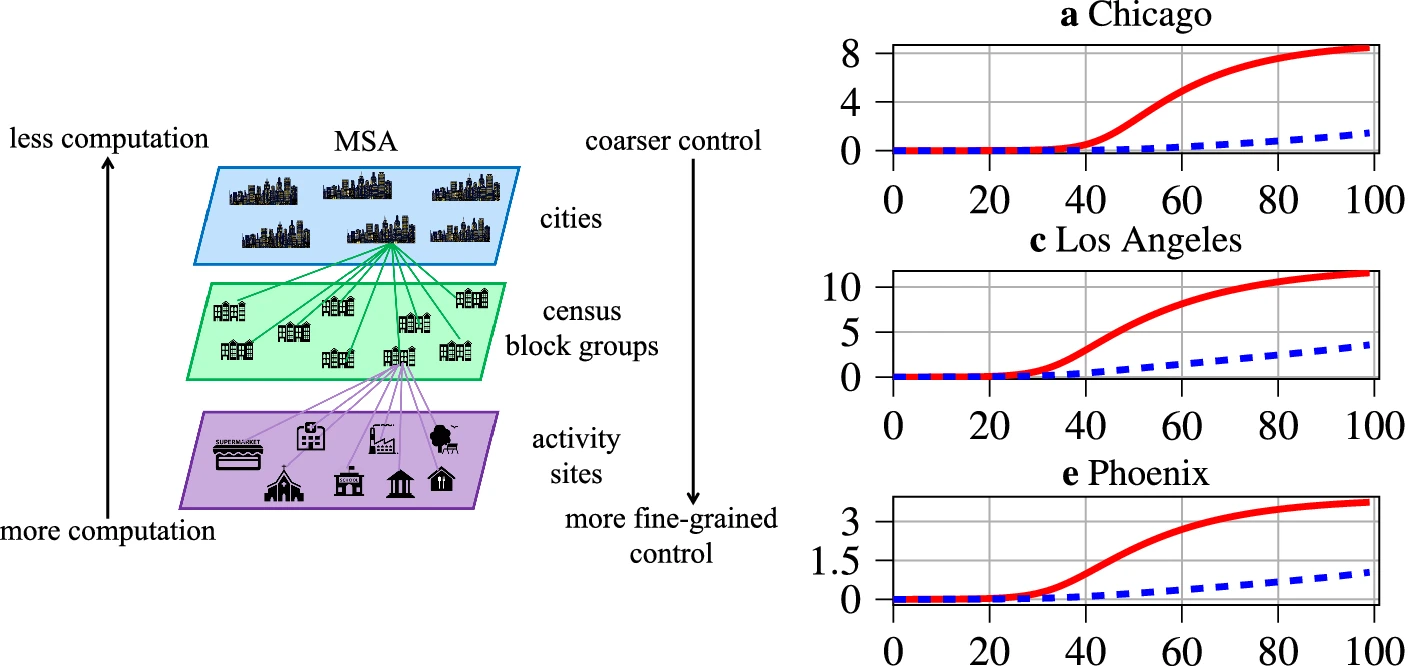 Scientific Reports 2022.
Scientific Reports 2022. -
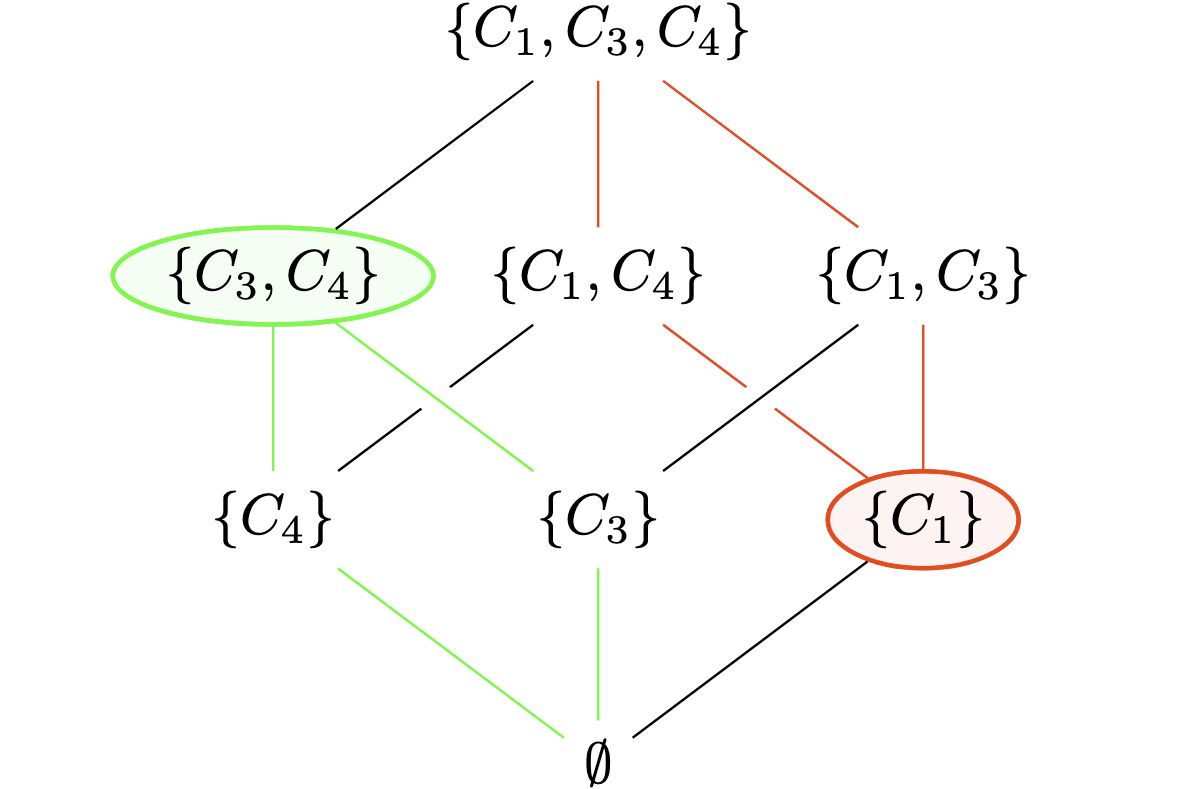 ICAPS XAIP Workshop 2019.
ICAPS XAIP Workshop 2019.


Powered by Jekyll and Minimal Light theme.